
David’s knowledge of SQL database systems and Identity Lifetime Manager is spectacular. His performance in envisioning and architecting Identity Management solutions is excellent and well directed. He is a gifted instructor, mentor and communicator. David’s speaking skills inform participant understanding and engagement with the complex technologies he has mastered. He possesses clear forethought regarding client needs. David is always willing to assist, participate in feedback on lessons learned, and step up to lead in new challenges. I highly endorse his work and his professional and personable style.
SSL v TLS with EntraID Sync and MIM's Generic LDAP Connector
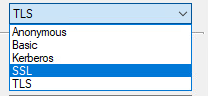
Everyone knows that SSL is vulnerable and we should therefore use TLS. What isn’t well understood is the options presented for Binding (authentication) when using the Generic LDAP Connector with AADConnect or the Generic LDAP ECMA 2.x with MIM. We are presented 5 options: Anonymous Basic Kerberos SSL TLS When we tested we could get the SSL option to work over port 636, and we could get the TLS option to work on port 389 but we couldn’t get the TLS option to work over port 636.